한 줄 요약 — 이 연구의 진단은 분명하다: AI 신뢰성의 병목이 데이터의 양이 아니라 검증 가능한 고가치 사실 데이터의 부재로 옮겨가고 있다는 것. 노신희의 워킹페이퍼(초고 v0.3)가 제안하는 진실저수지(Truth Reservoir)는 역설적으로 "진실을 저장하지 않는다." 대신 사실을 원자 명제 단위로 쪼개, 출처·증거·검증·반론·정정 이력과 함께 쌓아 사람과 AI가 스스로 진실을 추론할 입력값을 제공한다. 핵심은 "이 명제는 참인가"가 아니라 "이 명제가 지금 어떤 증거·검토 상태에 있는가"를 기록하는 것이다.
이 글은 노신희, 「진실을 저장하지 않는 진실저수지: 생성형 AI 시대의 고가치 사실 데이터 인프라에 관한 개념적·설계과학적 연구」(초고 v0.3, 2026) 를 정리한 것이다. 진실저수지는 아직 구축된 시스템이 아니라 제안된 개념·설계 인공물이며, 본문의 검증 사례는 작동 가능성을 보이는 시연이다. 대규모 실증은 후속 과제로 남아 있다.
왜 지금 이 이야기인가
AI 개발의 3요소는 흔히 데이터·알고리즘·컴퓨팅으로 요약된다. 알고리즘은 논문·오픈소스로 빠르게 퍼지고, 컴퓨팅은 자본과 인프라 계약으로 조달된다. 그러나 고품질 사실 데이터는 시간·검증 절차·도메인 지식·정정 이력이 쌓여야 형성되므로 단기간에 모방하기 어렵다. (앞서 우리가 정리한 "데이터 > 알고리즘 > 컴퓨팅" 논의와 같은 결의 진단이다.)
여기서 한 걸음 더 들어간다. LLM의 사실성 한계가 데이터 품질과 직결된다는 점은 환각(hallucination) 연구에서 반복 확인됐지만(Ji et al. 2023; Huang et al. 2024), 기존 데이터 품질 논의는 대부분 학습 데이터의 정확도·라벨 품질(데이터시트, 모델 카드, 데이터 진술 등)에 집중했다. 정작 AI가 실시간으로 참조하는 사회적 사실 데이터가 검증 가능한가라는 질문은 사각지대로 남았다. 정책·법률·의료·금융처럼 오류 비용이 큰 영역에서 문제는 데이터의 양이 아니라 그 데이터가 검증 가능한가라고 논문은 본다.
문제: 정보 오염은 '섞임'으로도 작동한다
지금 AI가 학습·참조하는 정보 생태계는 여러 형태의 정보 오염에 노출돼 있다. 논문은 이를 유형화한다(부록 B).
- 출처 없는 주장 — 근거 없이 떠도는 단정
- 사실과 해석의 혼합 — "X는 Y를 했다"와 "X는 Y를 잘했다"가 한 문장에
- 권위에 의한 검증 생략 — "유명 기관 발표니까"로 검증을 건너뜀
- 방법론 없는 측정값 — 표본·방법·기준이 빠진 통계
- 조용한 수정(silent edit) — 흔적 없이 사후에 바뀐 내용
- 선택 편향 — 무엇을 기록하고 무엇을 빼는가에서 생기는 치우침
논문이 특히 주목하는 건, 가장 위험한 오염이 명백한 거짓이 아니라, 다수의 검증된 사실 사이에 소수의 그럴듯한 오류가 섞이는 형태라는 점이다. 논문의 표현으로는 90%의 사실이 10%의 거짓에 신뢰성을 빌려준다. 그래서 표면적 검증으로는 걸러지지 않는다.

RAG만으로는 문서의 신뢰도까지 풀지 못한다
검색증강생성(RAG)은 외부 문서를 참조해 환각을 줄인다(Lewis et al. 2020). 하지만 참조되는 문서 자체의 신뢰도가 라벨링돼 있지 않다면, AI는 매 참조마다 신뢰도를 처음부터 판단해야 하고, 바로 그 과정에서 누락·비대칭·확증편향이 생긴다. 논문의 문제의식은 이렇다 — RAG는 "어디서 가져올까"는 풀지만 "가져온 그것이 검증된 사실인가"는 자동으로 풀지 않는다. 그 빈자리가 이 연구가 겨냥하는 지점이다.
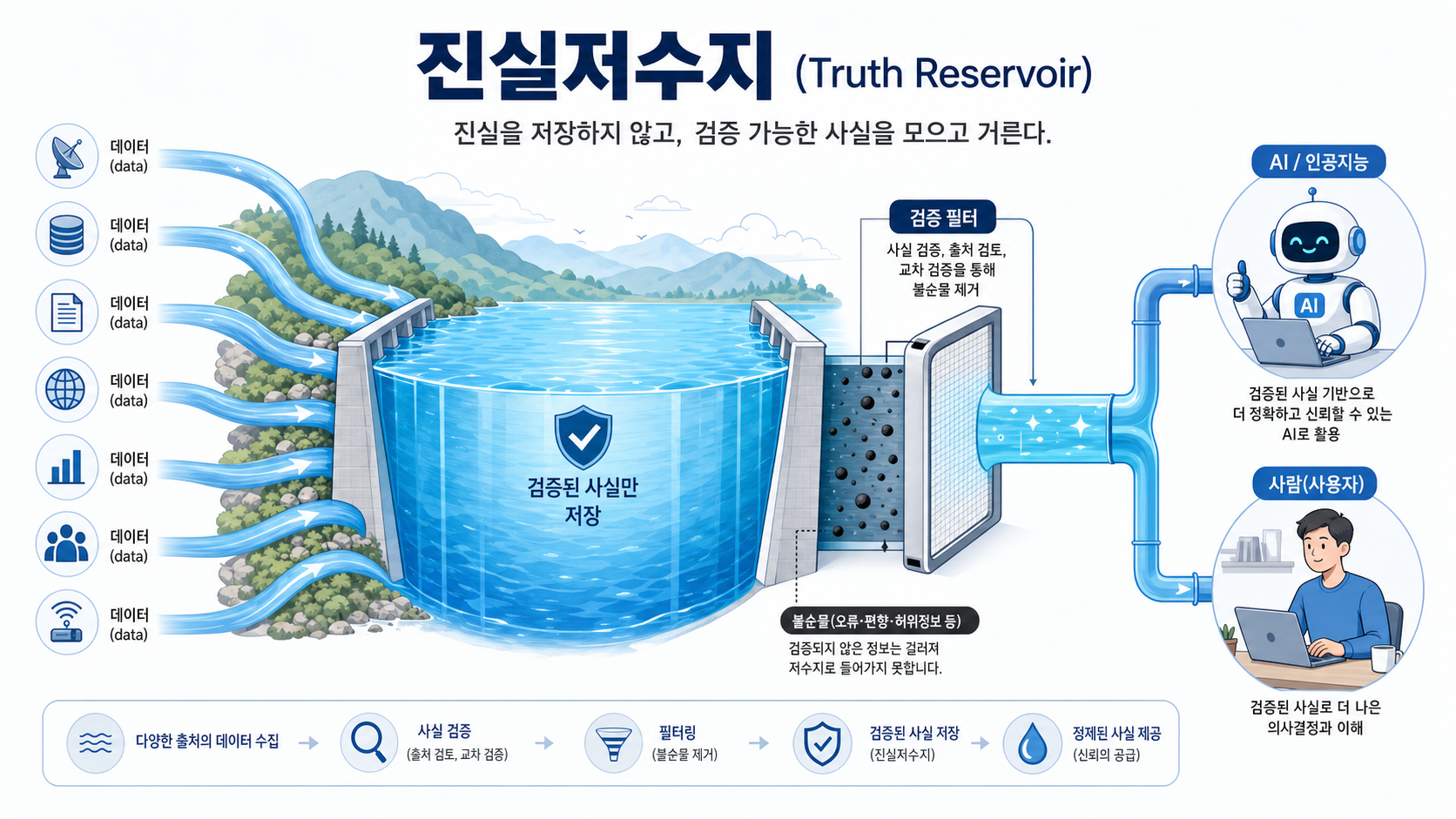
제안: '진실을 저장하지 않는' 진실저수지
진실저수지(Truth Reservoir) 는 진실 자체를 판정하거나 저장하지 않고, 진실 추론에 필요한 고가치 사실 데이터를 원자적 명제 단위로 구조화하여 그 출처·증거·검증 경로·반론·불확실성·정정 이력과 함께 축적·공개하는 공통 사실 기반 인프라다.
이름은 "진실저수지"인데 진실을 저장하지 않는다는 게 의도된 역설이다. 진실저수지가 보증하는 것은 명제의 참이 아니라, 그 명제가 어떤 증거·절차로 검증됐고 그 검증을 재현할 수 있다는 사실이다. 새 증거가 나오면 검증 라벨은 바뀐다.
비유는 저수지와 필터다 — 여러 출처의 물(사실)이 모이고(저장), 불순물을 걸러내며(정화), 필요할 때 공급한다(공급). 그리고 저수지가 물의 좋고 나쁨을 도덕적으로 판정하지 않듯, 진실저수지는 참·거짓을 직접 판정하지 않는다(판단 유보). 진실에 이르는 추론은 사람과 AI의 몫으로 남긴다. 논문은 진실 판정 알고리즘을 제안하지 않으며, 모든 사실을 담는 백과사전도 아니라고 분명히 선을 긋는다.

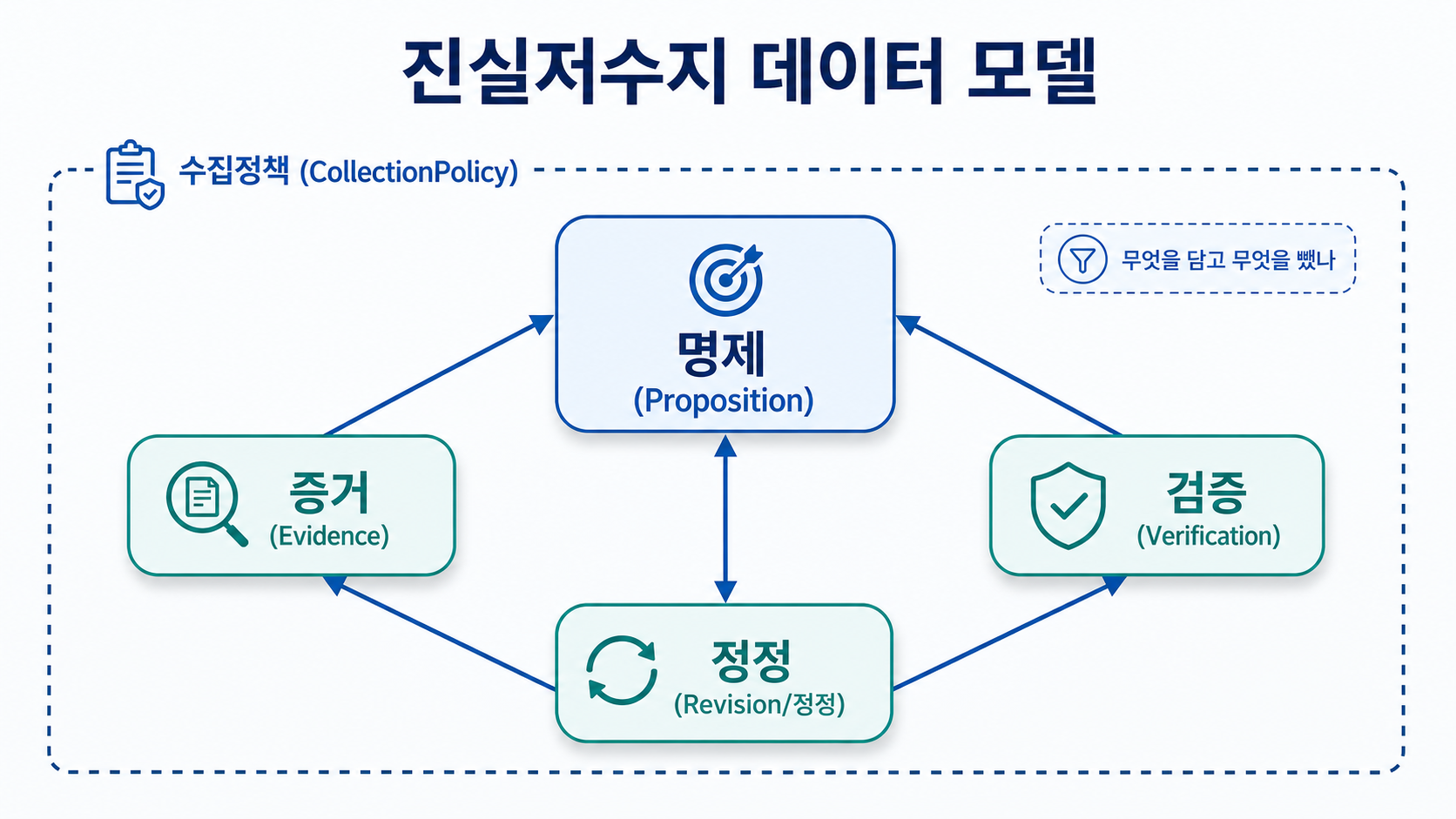
무엇을 저장하나: 명제·증거·검증·정정
데이터 모델은 네 핵심 객체 + 수집정책 객체로 이뤄진다.
| 객체 | 역할 | 담기는 것 |
|---|---|---|
| 명제(Proposition) | 가장 기본 단위 | 원자적 사실 명제, 유형(사건/문서/측정), 식별자, 시각 |
| 증거(Evidence) | 명제를 뒷받침 | 출처 URL, 원문 스냅샷·해시, 1차/2차 구분, 신뢰도 평가 |
| 검증(VerificationRecord) | 검증 과정 기록 | 검증자(사람/자동), 행동(지지·반박·보류), 반증 확인, 불확실성 메모, 사유 |
| 정정(RevisionRecord) | 수정 이력 | 이전/이후 내용, 정정 사유, 새 증거, 정정 주체·시각 |
| 수집정책(CollectionPolicy) | "무엇을 담고 뺐나" | 포함·제외 기준, 고가치 사유, 커버리지 한계, 편향 검토 주기 |
주목할 부분은 수집정책 객체다. 선택 편향 공개를 선언이 아니라 검토 가능한 설계로 바꾼다. 나아가 진실저수지 전체의 건강도는 정정 요청 처리율·방치 건수·처리 지연 중앙값으로 측정·공개하도록 설계한다(운영 시 공개 지표로 삼자는 제안이다) — 정정 의무가 말이 아니라 지표로 지켜지는지 보여주자는 것이고, 이 누적은 복제하기 어려운 장기 자산이 된다.
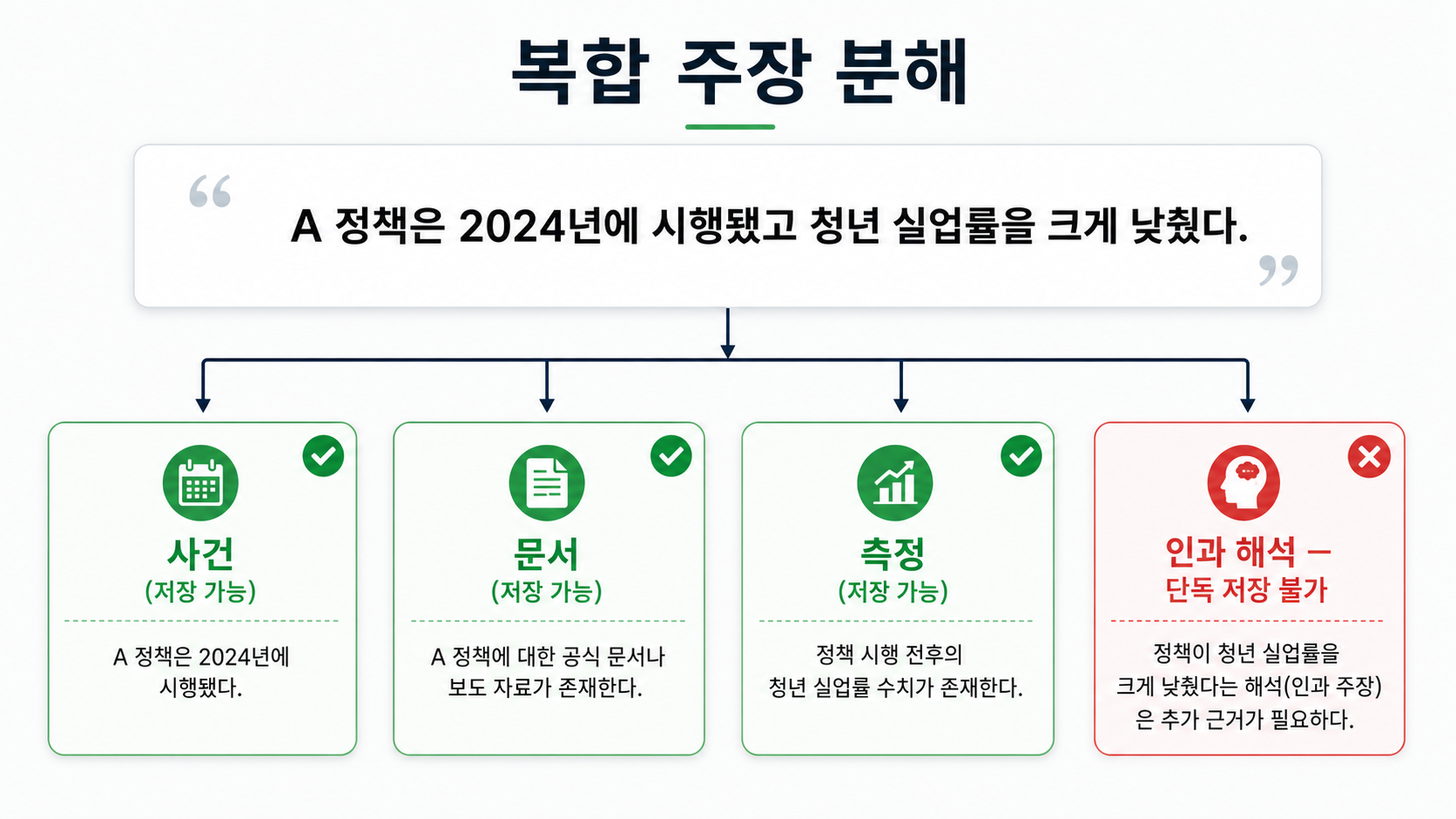
어떻게 쪼개나: 복합 주장의 분해
원리를 한 문장으로 보자. "A 정책은 2024년에 시행됐고, 그 결과 청년 실업률을 크게 낮췄다." 이 문장엔 사건·측정·인과 해석이 뒤섞여 그대로는 검증 단위가 못 된다. 진실저수지는 이렇게 쪼갠다.
| 분해된 명제 | 유형 | 저장 가능성 |
|---|---|---|
| A 정책은 2024년 ○월 ○일 시행됐다 | 사건 | 가능 |
| 정부 문서 X가 시행일을 그날로 기재한다 | 문서 | 가능 |
| 통계기관 Y가 2024년 청년 실업률을 Z%로 발표했다 | 측정 | 가능 |
| A 정책이 청년 실업률을 낮췄다 | 인과 해석 | 단독 저장 불가 |
| 기관 B는 보고서 C에서 "정책이 기여했다"고 주장했다 | 문서 내용 | 가능 |
| 기관 D는 보고서 E에서 "주원인은 경기 회복"이라 주장했다 | 문서 내용 | 가능 |
핵심은 인과 해석은 단독으로 저장되지 않으면서도, 그에 관한 대립 주장은 각각 "문서 내용 명제"로 보존된다는 점이다. 어느 해석이 옳은지 판정하지 않고 대립의 존재만 사실로 보존한다. 사실과 해석은 분리되지만, 사용자는 인과에 관한 정보를 잃지 않는다.
실제로 검증해 보면: 아폴로 11호
논문은 정치적으로 중립적인 사안으로 실제 1차 출처 검증을 시연한다. 종합 명제는 "1969-07-20 20:17:40(UTC), 암스트롱·올드린이 이글호를 조종해 고요의 바다에 착륙했다." 이 문장은 5W1H를 갖췄지만 검증 구조에선 여러 요소(시각·장소·승무원·물리 흔적·역반사경)가 섞여 있어, 원자성 원칙에 따라 하위 명제로 쪼갠다.
- NASA 임무 기록이 착륙 시각을 1969-07-20 20:17:40 UTC로 기재한다 — 문서 내용 (NASA NSSDCA)
- 달 정찰 궤도선(LRO) 이미지에 착륙지 물리 흔적이 관측된다 — 측정/관측
- 설치된 레이저 역반사경이 독립 관측소의 거리 측정에 쓰여 왔다 — 측정(재현)
여기서 증거가 어느 하위 명제를 지지하는지를 명시하는 게 정밀함의 핵심이다. 레이저 역반사경은 매우 강한 물리·재현 증거지만, "암스트롱이 그 시각에 조종했다"를 단독으로 증명하진 않는다. 그것이 직접 지지하는 건 "달 표면에 독립 관측으로 거리 측정이 가능한 역반사 장치가 존재한다"는 명제이며, 이는 착륙 사실 전체에 대한 강한 보강 증거다.
논문은 이 명제를 축약하면 이런 객체로 기록할 수 있다고 보인다(전체 레코드는 별도 공개 결과물로 언급되나, 이 칼럼에는 접근 경로가 없어 공개 범위는 확인이 필요하다).
Proposition ID: TR-EVT-APOLLO11-001 / Type: document_content
Atomic: NASA 임무 기록은 이글호 착륙 시각을 1969-07-20 20:17:40 UTC로 기재한다
Excluded interpretation: 냉전적 의미·인류사적 평가·착륙 동기
Evidence: NASA NSSDCA Apollo 11 record (식별자·접근경로·shortQuote·해시)
Procedure state: human_reviewed; counterevidence_checked; no_material_unresolved_conflict
Evidence state: independently_supported / Revision history: none주목할 점 — 진실저수지는 "이 명제는 참이다", "완전 신뢰 가능" 같은 진실 판정을 부여하지 않는다. 설계상 보증하려는 건 "이 사건은 이러한 독립 증거로 검증됐고, 적절한 장비·절차를 갖춘 독립 관측자가 그 검증을 재현할 수 있다" 까지다.
대표적 반대 가설(달 착륙 음모론)도 출처 단위로 배제하지 않고 명제·증거 단위로 검토하되, 재현 가능한 반증이 없으면 사실과 동등하게 놓지 않는다 — 반대 목소리의 존재가 곧 타당성은 아니라는 취지다.

11개 설계 원칙 (헌법)
진실저수지가 진실 판정 기관으로 변질되지 않도록 잡아 주는 헌법적 장치다.
| 원칙 | 뜻 |
|---|---|
| 사실/해석 분리 | "했다"(사실)와 "잘했다"(해석)를 나눠 저장 (최상위) |
| 명제 원자성 | 복합 주장을 더 못 쪼갤 단위까지 분해 |
| 사건·문서·측정 3분류 | 유형에 맞는 검증 절차·증거를 명확히 |
| 증거 우선 | 1차 출처 우선, 증거 없는 명제는 저장 불가 |
| 검증 가능성 | 제3자가 재현 가능한 검증 절차 |
| 판단 유보 | 증거 부족·상충이면 결론을 강요하지 않고 명시 |
| 공개 정정 | 모든 정정은 전후·사유·주체·시각이 공개 이력으로 |
| 출처 독립성 | 한 원천의 반복 인용은 하나의 출처로 |
| 인간 책임 | AI 자동 판정은 최종 권위가 될 수 없음 |
| 선택 편향 공개 | 무엇을 담고 뺄지의 기준 자체를 공개 |
| 엔티티 중립성 | 인물·기관은 탐색 허브일 뿐, 기본 단위는 명제 |
기존 인프라와 무엇이 다른가
위키백과·팩트체크·지식그래프·Truth Discovery·RAG와 비교하면 차이가 또렷하다(논문 표 4).
| 구분 | 위키백과 | 팩트체크 | 지식그래프 | Truth Discovery | RAG DB | 진실저수지 |
|---|---|---|---|---|---|---|
| 기본 단위 | 문서 | 주장 | 엔티티/관계 | 데이터 항목 | 문서 청크 | 원자 명제 |
| 목적 | 설명 | 주장 검증 | 지식 연결 | 참값 추정 | 답변 보조 | 추론 지원 |
| 진실 판정 | 제한적 | 강함 | 약함 | 점수화 | 없음 | 하지 않음 |
| 정정 이력 | 존재 | 매체별 | 약함 | 약함 | 약함 | 핵심 구성 |
| 인간 역할 | 편집자 | 검증자 | 구축자 | 제한적 | 없음 | 고위험 필수 |
특히 Truth Discovery(여러 출처가 충돌할 때 신뢰도를 가중해 알고리즘으로 "참값"을 출력; Li et al. 2016)와의 구별이 독창성을 규정한다. Truth Discovery는 참값을 출력하지만, 진실저수지는 참값을 산출하지 않고 *검증 가능한 명제와 증거·반론·정정 이력을 저장해 추론을 사람·AI에 위임한다. 전자는 점수화된 권위화의 위험을 안고, 후자는 판단 유보와 반증 가능성을 정당한 상태로 둔다. 결론은 대체가 아니라 보완 — 진실저수지는 기존 인프라 아래에서 사실을 떠받치는 하부 인프라*다.
어디에 쓰나
각 명제가 증거 상태·절차 상태 라벨(자동 처리인지/인간 검수인지/현재 이의제기 중인지)과 재현 가능한 검증 경로를 갖추므로, 진실저수지의 데이터는:
- 학습 데이터 정제의 기준 데이터
- RAG의 참조원 — 신뢰도가 미리 라벨링된 참조처
- 모델 평가의 사실성 기준
- 공공 의사결정의 사실 기반
으로 쓸 수 있다. 단, 라벨은 AI가 받아들여야 할 최종 진실 판정이 아니라 근거와 불확실성을 표시하는 입력이다(인간 책임 원칙).
정직한 한계
논문은 예상 비판을 별도 절에서 직접 다룬다.
- "사실과 해석을 완전히 분리할 수 있나?" — 못 한다. 관찰의 이론적재성상 순수한 사실은 없고, "무엇을 했다"로 자르는 것조차 이미 해석을 담는다. 논문은 이를 수용한다. 목표는 혼합을 제거가 아니라 줄이고, 그 한계를 공개하는 절차적 지향이다.
- "고가치 선별이 곧 가치판단 아닌가?" — 맞다. 그래서 선별 기준 자체를 공개해 편향을 숨기지 않고 드러내는 재귀적 정직성을 강점으로 삼는다(여기서 고가치는 도덕적 우열이 아니라 영향·참조 빈도·오류 비용·논쟁성을 뜻한다).
- "인간 검수가 확장을 막지 않나?" — 인간 책임의 핵심은 모든 명제의 직접 검수가 아니라 AI 판정이 최종 권위가 되지 않음에 있다. 자동 처리의 범위·표시·사후 감사로 확장과 책임을 양립시킨다.
- "결국 진실 판정 기관으로 변질되지 않나?" — 판단 유보·인간 책임·선택 편향 공개가 바로 그 변질을 막는 헌법적 장치다.

왜 중요한가
검증된 사실의 공통 기반이 없으면 진실 추론 자체가 불가능하다. 진실저수지가 파는 것은 "진실"이라는 완제품이 아니라, 진실에 도달하기 위한 검증 가능한 입력값이다. 그리고 그 장기 가치는 숨긴 도구가 아니라 공개된 채 쌓이는 검증 기록 — 정정 이력·반론·오류율 — 의 두께에 있다. 알고리즘은 베끼고 GPU는 사면 되지만, 시간을 들여 검증·정정한 사실의 누적은 단기간에 모방하기 어렵다. 이 연구의 관점에서는, AI 시대의 해자가 데이터라면 그중에서도 검증 가능한 사실 데이터야말로 복제하기 어려운 장기 자산이 된다.
정리
- 이 연구의 진단: AI 신뢰성의 병목이 양 → 검증 가능성으로 이동 중이다.
- 진실저수지는 진실을 저장하지 않고, 사실을 원자 명제 + 증거·검증·정정으로 쌓아 추론의 입력값을 제공한다.
- "이 명제는 참인가"가 아니라 "지금 어떤 증거·검토 상태인가"를 기록한다 — 그래서 판단 유보와 반증이 정당한 상태가 된다.
- 아직 개념·설계 단계다. 대규모 실증(특히 일반 RAG vs 진실저수지 기반 RAG 비교)은 후속 과제다.
참고
- 노신희, 「진실을 저장하지 않는 진실저수지: 생성형 AI 시대의 고가치 사실 데이터 인프라에 관한 개념적·설계과학적 연구」, 초고(Working Draft) v0.3, 2026.
- Ji et al. (2023) Survey of hallucination in NLG, ACM Computing Surveys; Huang et al. (2024) A survey on hallucination in LLMs.
- Lewis et al. (2020) Retrieval-augmented generation, NeurIPS. / Li et al. (2016) A survey on truth discovery, ACM SIGKDD.
- Gebru et al. (2021) Datasheets for datasets; Mitchell et al. (2019) Model cards; Bender & Friedman (2018) Data statements.
- Hevner et al. (2004) / Peffers et al. (2007) Design Science Research. / Wikipedia core content policies (NPOV·Verifiability·NOR, 2024).
- 관련 배경 문헌으로 논문이 언급한 표준: NIST AI RMF 1.0(2023), C2PA(2023), W3C PROV-O(2013), FAIR Principles(2016), EU AI Act(2024).


