한 줄 결론 — 엔비디아가 중국 Z.ai(지푸 AI)의 오픈웨이트 초거대 모델 GLM-5.2를 자사 4비트 포맷 NVFP4로 양자화해 허깅페이스에 공개했다. 핵심은 4비트로 내렸는데도 공식 벤치마크가 FP8과 사실상 동급이라는 것 — 총 753B(활성 40B)짜리 초거대 MoE를 훨씬 적은 GPU에 올릴 길이 열린 셈이다. 이 글은 양자화가 뭔지부터 풀고, NVFP4·MoE·오픈웨이트를 초보자 눈높이로 정리하며, 흔히 잘못 도는 수치(파라미터·용량·'디코딩 24%')를 공식 모델카드 기준으로 정확히 짚는다.

1. 무슨 일인가
엔비디아가 GLM-5.2를 NVFP4(4비트)로 양자화한 버전을 공식 모델카드(게시 2026-06-25)와 함께 허깅페이스에 올렸다(모델카드에 따르면 MoE expert 내부 transformer block의 linear 연산에 대해 가중치와 활성값을 NVFP4로 양자화했고, shared expert는 제외된다). 모델카드는 "vLLM·SGLang으로 바로 추론 가능"이라 안내하고, vLLM·SGLang(lmsys)도 각각 서빙 준비·당일 지원을 알렸다. [확인/보도강함]
가장 인상적인 건 정확도다. 4비트로 내렸는데도 공식 모델카드가 제시한 5개 벤치마크가 FP8 기준과 거의 붙어 있다. [확인]
| 벤치마크 | 원본(FP8) | NVFP4(4비트) |
|---|---|---|
| GPQA Diamond | 89.52 | 89.39 |
| IFBench | 74.95 | 75.81 |
| AA-LCR | 69.38 | 70.13 |
| SciCode | 49.85 | 49.04 |
| τ²-Bench Telecom | 97.90 | 98.25 |
몇몇 항목은 오히려 소폭 올랐다(양자화 과정의 자연스러운 변동 범위로 본다). 요점은 "이 5개 벤치마크에서는 4비트인데도 FP8과 거의 같은 수준"이라는 것 — 단, 이는 제시된 항목에 한정된 결과이지 일반 성능 전체의 보장은 아니다.

2. 숫자부터 정확히 짚자
이런 스펙 뉴스는 여러 곳으로 옮겨지며 숫자가 미세하게 틀어지곤 한다(파라미터를 10배로, 용량 라벨을 뒤바꾸는 식). 헷갈리기 쉬운 세 가지를, 공식 모델카드(1차 출처) 기준으로 정확히 정리한다.
- ① 파라미터 = 총 753B(7,530억) · 활성 40B. 공식 모델카드는 "Number of Model Parameters: 753B in total and 40B activated"라고 적는다. 즉 총 7,530억 파라미터이고, 그중 한 번에 40B(400억)만 활성되는 구조다(총 파라미터는 출처에 따라 744B로도 표기되나 반올림 편차). 흔히 도는 '75.3억/753억' 표기는 10배 어긋난 값이니 주의. [확인]
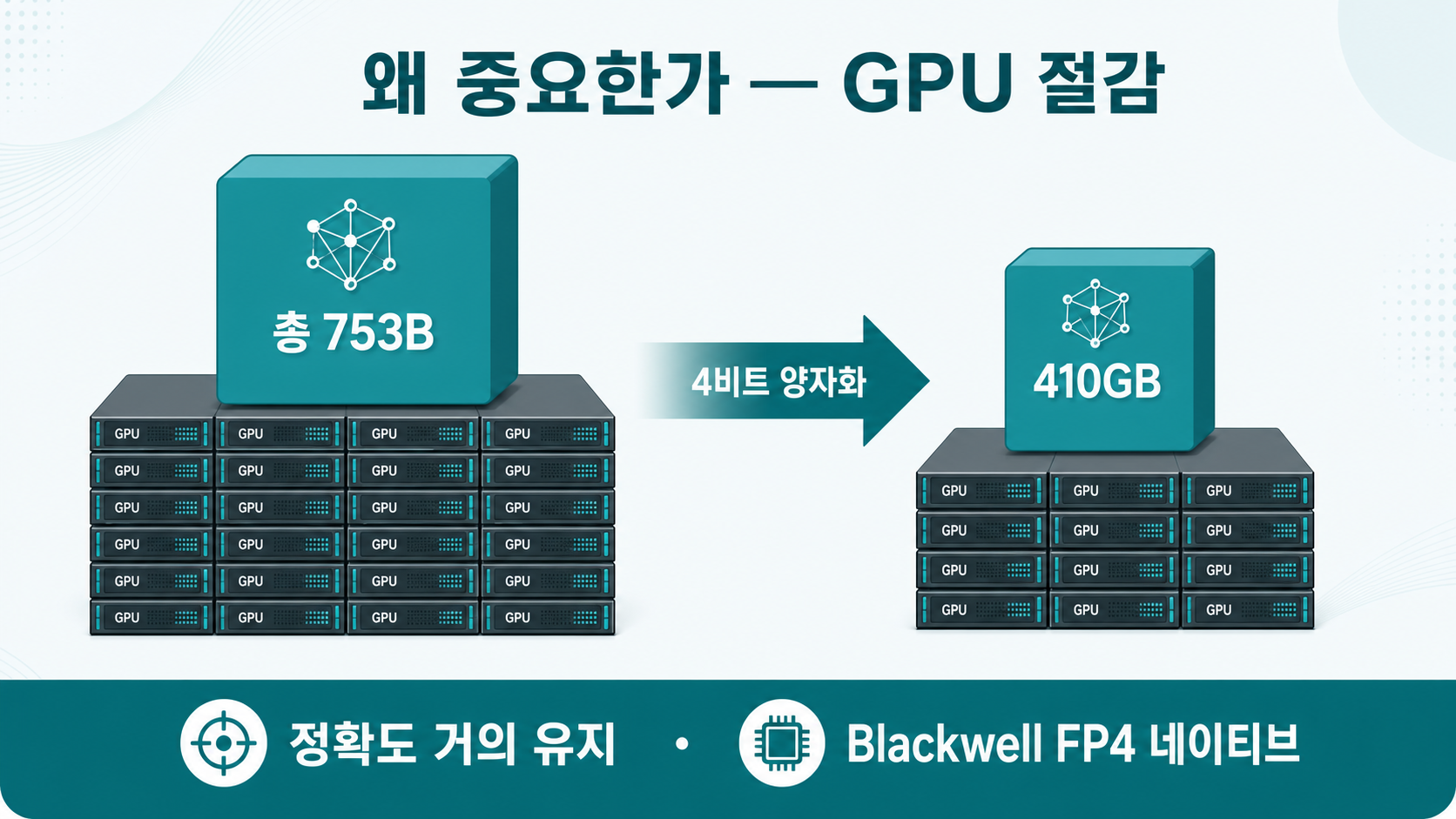
- ② 1.5TB는 FP8이 아니라 BF16 용량. 산수로 맞춰보면 명확하다. 753B × 2바이트(BF16) ≈ 1.5TB, 753B × 1바이트(FP8) ≈ 0.75TB(750GB). "1.5TB(FP8)" 라고 도는 표기는 BF16 용량을 FP8로 잘못 라벨링한 것이다. [확인]
- ③ '감소율'은 기준을 밝혀야 성립. 양자화본은 약 410~465GB다(요약본은 410GB, HF 실제 파일 합계는 ~465GB). BF16(1.5TB) 대비면 ~3.7배(≈73%↓), FP8(750GB) 대비면 약 1.6~1.8배(410GB면 ~1.8배, 465GB면 ~1.6배 — AlphaSignal 등 요약이 '1.8배'로 표기)다. "FP8 1.5TB → 410GB, 73%↓"처럼 쓰면 기준이 뒤섞여 내부 모순이 된다(FP8이 기준이면 73%가 안 나온다). 즉 기준선(BF16/FP8)을 반드시 병기해야 한다. [확인]

💡 MoE(전문가 혼합, Mixture-of-Experts)란 — 모델 안에 여러 '전문가' 서브네트워크를 두고, 입력 토큰마다 그중 일부만 켜서 계산하는 구조. GLM-5.2는 전문가 256개 중 토큰당 8개만 활성한다. 그래서 총 753B이지만 실제 연산은 40B만큼만 든다 — "덩치는 크지만 매번 다 쓰지는 않는다."
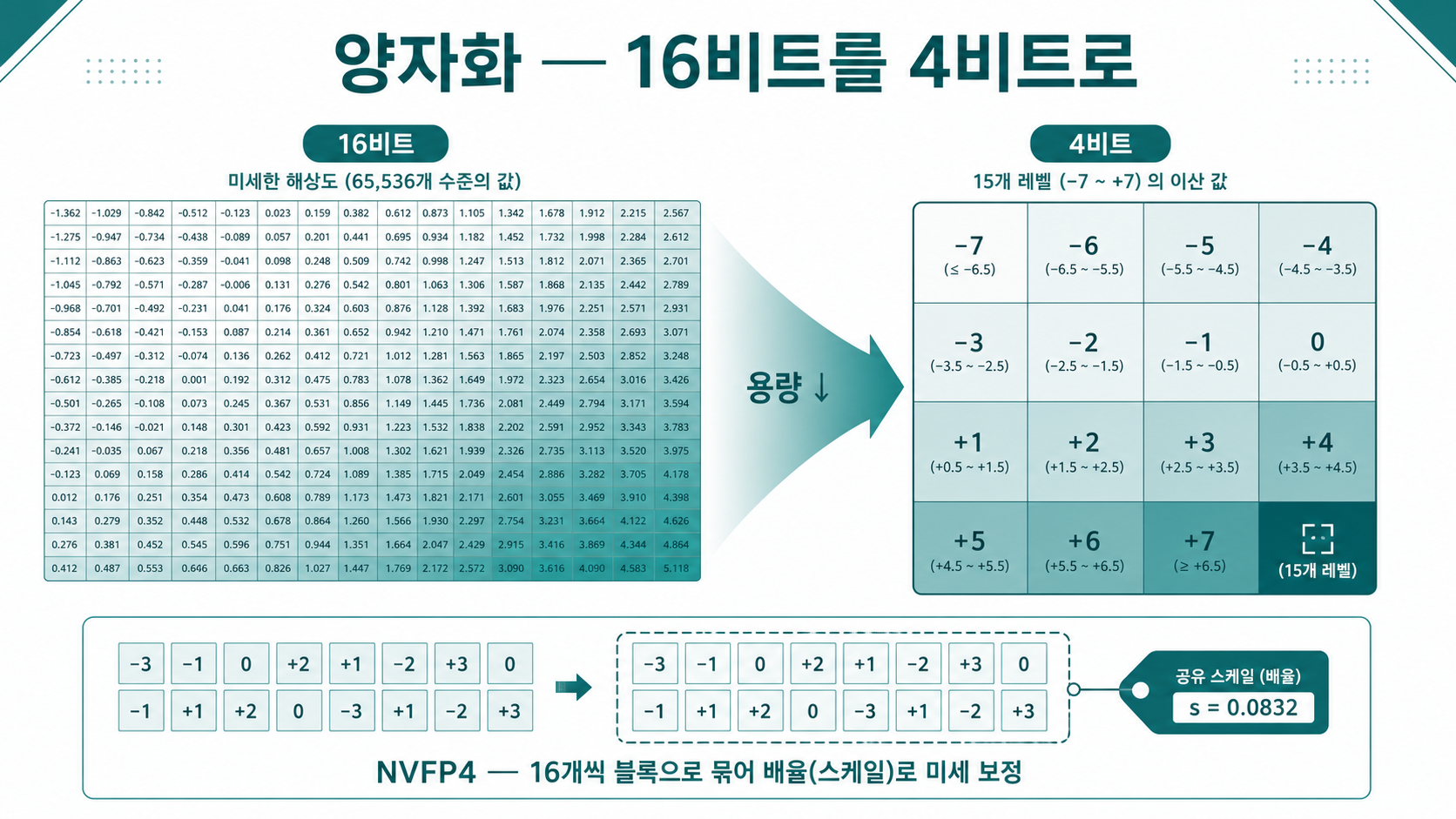
3. 용어풀이 — 양자화와 'NVFP4'
💡 양자화(quantization) — 모델의 가중치(숫자들)를 더 적은 비트로 표현해 용량과 GPU 메모리를 줄이는 것. 사진 파일을 적당히 압축해 용량을 줄이는 것과 비슷한 효과를 노린다(원리가 같진 않다). 관건은 줄이면서도 품질(정확도)을 얼마나 지키느냐다.
숫자 하나를 몇 비트로 담느냐에 따라 이름이 다르다 — BF16(16비트), FP8(8비트), 그리고 FP4(4비트). 비트가 줄면 용량은 확 주는데, 보통 정밀도(품질)가 깎인다. NVFP4는 그 손실을 최소화한 엔비디아의 4비트 부동소수점 포맷으로, 최신 Blackwell GPU 세대와 함께 나왔다.
어떻게 4비트인데 정확도를 지킬까? 핵심은 2단계 마이크로스케일링이다.
- 4비트가 표현할 수 있는 값은 15가지뿐이다(±0.5·±1·±1.5·±2·±3·±4·±6·0). 좁다.
- 그래서 값 16개를 한 블록으로 묶어, 블록마다 FP8 배율(스케일)을 하나씩 공유하고, 텐서 전체엔 FP32 배율을 하나 더 둔다. 좁은 4비트 눈금을 각 블록의 실제 값 분포에 맞춰 미세 조정하는 셈이다.
- 이전 포맷 MXFP4는 블록이 32개에 배율이 2의 거듭제곱(E8M0)이다. NVFP4는 블록을 16으로 줄이고 배율을 FP8로 써서 양자화 오차를 더 잘게 줄이도록 설계됐다 — 이게 '4비트인데 정확도 유지'의 주된 이유로 설명된다. [확인]
💡 NVFP4 vs INT4(GPTQ·AWQ) — 흔히 쓰는 GPTQ·AWQ는 대개 정수(INT4) 방식이고 주로 가중치를 줄인다. NVFP4는 부동소수점이고 (위 범위 안에서) 가중치+활성값을 4비트로 다루며, Blackwell의 FP4 텐서코어에서 네이티브 가속된다. 대신 H100·A100 등 Blackwell 이전 GPU엔 FP4 네이티브 가속이 없어 이점을 못 살린다 — 그땐 GPTQ/AWQ INT4가 현실적이다.
4. GLM-5.2란
💡 오픈웨이트(open-weight) — 모델의 학습된 가중치를 공개해 누구나 내려받아 직접 돌릴 수 있게 한 것. (완전 오픈소스와는 다르지만, 갖다 쓰기엔 충분하다.)
- 개발사: 중국 Z.ai(지푸 AI, 智谱) — 허깅페이스 조직명
zai-org. - 라이선스: MIT(지역 제한 없음)로 BF16·FP8 가중치를 공개 → vLLM 등으로 자체 서빙 가능. [확인]
- 구조: MoE 총 744~753B / 활성 약 40B, 컨텍스트 최대 100만(1M) 입력 토큰·출력 최대 131,072 토큰. [확인]
- 성능·가격: Z.ai는 SWE-bench Pro 62.1로 GPT-5.5(58.6)를 앞섰다고 제시하고, 가격은 백만 토큰당 약 입력 $1.40 / 출력 $4.40로 GPT-5.5·Claude Opus의 약 1/6이라고 주장한다(벤치·가격은 대체로 벤더 자체 발표를 매체가 옮긴 것). [보도강함] — 주간 TOP10에서도 다뤘던 '중국 오픈모델의 프런티어 추격'을 상징하는 사례다.

5. 왜 중요한가
핵심은 경량화 → GPU 절감이다. 총 753B급 초거대 MoE를 (제시된 벤치마크 기준)정확도 손실 거의 없이 FP8 대비 약 1.6~1.8배(BF16 대비 ~3.7배) 작게 만들면, 필요한 GPU 메모리·노드 수가 줄어 서빙 비용이 내려간다. 게다가 NVFP4는 Blackwell FP4 텐서코어에서 네이티브 가속돼 역양자화 오버헤드를 크게 줄인다(스케일 처리 비용 자체가 0이라는 뜻은 아니다). [확인]
한 겹 더 있다. GLM-5.2는 MIT 라이선스·Global 배포로 공개돼 상업·비상업 활용이 가능하다고 안내된다(단 실제 배포엔 각 지역 규제·조직별 검토가 따른다). "초거대 오픈모델을 더 적은 GPU에" 라는 흐름은 프런티어 성능을 소수 대형 사업자에서 더 넓은 손으로 퍼뜨린다.
6. 정직한 함정
경량화 뉴스는 장점만 실리기 쉬운데, 이 체크포인트엔 분명한 단서가 붙는다.
- '디코딩 24% 감소'는 엔비디아 공식 수치가 아니다. 공식 모델카드엔 속도 저하·24% 언급이 아예 없다. 이 수치의 실제 출처는 한 개발자(Jonathan Washburn)가 8×B200에서 FP8→NVFP4로 바꿔보고 롤백한 단일 배포 후기다("NVFP4엔 MTP 추측 디코딩이 없어 단일 스트림이 ~24% 느려졌다"). 즉 특정 워크로드·구성에 종속된 값이지 보편 수치가 아니다. [보도강함/단정어려움]
- 다만 메커니즘은 있다. "MTP(다중 토큰 예측)가 없으면 디코딩이 급락한다"는 지적은 허깅페이스 공식 토론에서도 독립적으로 나온다. 단 '24%'라는 구체 숫자를 검증하진 않는다. [확인 — 메커니즘]
- Blackwell 전용이라는 하드웨어 종속. NVFP4 가속은 Blackwell에서만 된다. 한 사용자는 "NVFP4는 블랙웰에서만 된다. 나머지에겐 GGUF Q4가 훨씬 싼 하드웨어로 품질 90%를 준다"고 꼬집었다(2차 재현 인용). [보도강함]
- 실사용 이슈도 보고됐다. 허깅페이스 토론엔 특정 배포에서 "TAU2 점수가 0.8154에 그친다", "NVFP4 KV 캐시가 MLA 백엔드와 호환 안 됨" 같은 리포트가 올라와 있다. [확인]

7. 커뮤니티 반응
(정직 고지: 검증 가능한 원문이 빈약하다. Reddit r/LocalLLaMA는 크롤러 차단, X는 유료화로 축자 확인 불가. 직접 열리는 1차 원문은 허깅페이스 공식 토론뿐이고, X 반응은 2차 재현 인용에 의존한다.)
- 하드웨어 락인 회의: "오픈웨이트인데 결국 블랙웰 전용이라니 — 나머지에겐 GGUF Q4가 저렴한 하드웨어로 품질 90%를 준다." (X 발언의 Digg 2차 재현 인용)
- 양자화 품질 회의: "이 회사 양자화는 내 경험상 다국어 성능을 꽤 깎더라." (X 발언의 Digg 2차 재현 인용 — 위 허깅페이스 토론의 실사용 이슈와도 맞물린다.)
- 엔진 측 환영: vLLM·SGLang이 서빙 준비·당일 지원을 알렸다(다만 이건 벤더/엔진 홍보 성격).
- 지정학 각도는 미확인: '엔비디아가 중국 오픈모델을 최적화했다'는 미·중 맥락의 커뮤니티 논평은 검증 가능한 원문으로 확인하지 못했다. 지어내지 않고 미확인으로 둔다.
왜 숫자를 정확히 봐야 하나
작은 차이 같지만, '753억'과 '753B'는 10배다 — 모델의 실제 규모(그리고 필요한 GPU)를 완전히 다르게 이해하게 만든다. '1.5TB=FP8'이라는 라벨 혼동은 양자화의 압축률 자체를 오독하게 한다. 하나의 발표가 여러 곳으로 옮겨지며 숫자가 미세하게 틀어지는 건 흔한 일이라 — 공식 모델카드(1차 출처)로 한 번 맞춰보는 습관이 이 뉴스가 주는 실용적 교훈이다.

최종 정리
- 사실: 엔비디아가 GLM-5.2를 NVFP4(4비트)로 양자화해 HF 공개. 정확도는 FP8과 사실상 동급(공식 벤치). [확인]
- 정확한 값: 총 753B·활성 40B MoE / 1.5TB는 BF16(FP8은 ~750GB) / 감소율은 기준 병기(BF16 대비 ~3.7배·FP8 대비 ~1.6~1.8배) — 공식 모델카드 기준. [확인]
- 함정: '24% 디코딩 감소'는 엔비디아 아닌 단일 개발자 후기(워크로드 종속), NVFP4는 Blackwell 전용, 실사용 이슈 보고. [보도강함/확인]
- 의미: 초거대 MoE를 더 적은 GPU에 — MIT 오픈웨이트라 확산력이 크다. 커뮤니티 원문은 빈약(표본 제한).
초보자용 용어 사전
- 양자화 — 가중치를 적은 비트로 표현해 용량·메모리를 줄이는 것.
- 비트 포맷(BF16·FP8·FP4) — 숫자 하나를 16/8/4비트로 담는 방식. 작을수록 용량↓·정밀도↓.
- NVFP4 — 엔비디아의 4비트 부동소수점 포맷(Blackwell). 마이크로스케일링으로 정확도 유지.
- MoE(전문가 혼합) — 여러 전문가 중 토큰마다 일부만 켜는 구조. 총 파라미터 ≫ 활성 파라미터.
- 총/활성 파라미터 — 전체 크기 vs 한 번에 실제로 쓰는 크기(MoE에서 다름).
- 컨텍스트 길이 — 한 번에 넣을 수 있는 입력 토큰 수(GLM-5.2는 최대 100만).
- 오픈웨이트 — 학습된 가중치를 공개해 직접 내려받아 돌릴 수 있게 한 것.
- GPTQ·AWQ / GGUF — 다른 양자화 방식·포맷(주로 INT4). Blackwell 없이도 씀.
출처
- 1차(공식): NVIDIA GLM-5.2-NVFP4 모델카드 · 파일 트리(~465GB) · 공식 토론 · GLM-5.2 원 모델·MIT
- NVFP4 기술: NVIDIA 개발자 블로그 · NVIDIA Research
- 2차(요약·보도): vLLM Recipes(BF16 1.5TB→410GB·MoE 세부) · AlphaSignal('1.8×') · VentureBeat(성능·가격)
- 참고(국내 보도): AI타임스(2026-06-27) — 이 글은 위 1차 출처를 직접 확인해 독립적으로 작성했으며, 수치는 공식 모델카드 기준이다.
※ 이 글은 공식 모델카드·엔비디아 기술문서 등 1차 출처를 직접 확인해 독립적으로 작성했다(국내 보도는 참고). 성능·가격은 상당 부분 벤더(Z.ai) 자체 발표를 매체가 옮긴 것이며, '24% 디코딩 감소'는 엔비디아 공식 수치가 아니라 단일 개발자 배포 후기다. 파라미터·용량 수치는 NVIDIA/Z.ai 공식 모델카드 기준이다. 커뮤니티 인용은 원문 직접 확인이 제한돼(Reddit 차단·X 유료화) 2차 재현에 의존한 제한 표본이다. 삽화는 AI로 생성한 개념 이미지다.


